Speed benchmarks#
import torch
from medusa.benchmark import FancyTimer
from medusa.detect import SCRFDetector, YunetDetector
torch.set_grad_enabled(False)
timer_ = FancyTimer()
params = {
"model_cls": [SCRFDetector, YunetDetector],
"device": ['cuda', "cpu"],
"batch_size": [1, 2, 4, 8, 16, 32, 64, 128, 256, 512]
}
from medusa.data import get_example_image
for p in timer_.iter(params):
if p["model_cls"] == YunetDetector and p["device"] == "cuda":
continue
model = p["model_cls"](device=p["device"])
img = get_example_image(device=p["device"])
img = img.repeat(p["batch_size"], 1, 1, 1)
with torch.inference_mode():
timer_.time(model, [img], n_warmup=3, repeats=20, params=p)
torch.cuda.empty_cache()
df_detect = timer_.to_df()
0%| | 0/40 [00:00<?, ?it/s]
0%| | 0/40 [00:00<?, ?it/s]
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[2], line 9
6 continue
8 model = p["model_cls"](device=p["device"])
----> 9 img = get_example_image(device=p["device"])
10 img = img.repeat(p["batch_size"], 1, 1, 1)
12 with torch.inference_mode():
File ~/work/medusa/medusa/medusa/data/example_data.py:79, in get_example_image(n_faces, load, device, channels_last, dtype)
77 imgs.append(f)
78 else:
---> 79 img = read_image(str(f)).to(device)
80 if channels_last:
81 img = img.permute(1, 2, 0)
File ~/.cache/pypoetry/virtualenvs/medusa-2VgPi4zZ-py3.10/lib/python3.10/site-packages/torch/cuda/__init__.py:247, in _lazy_init()
245 if 'CUDA_MODULE_LOADING' not in os.environ:
246 os.environ['CUDA_MODULE_LOADING'] = 'LAZY'
--> 247 torch._C._cuda_init()
248 # Some of the queued calls may reentrantly call _lazy_init();
249 # we need to just return without initializing in that case.
250 # However, we must not let any *other* threads in!
251 _tls.is_initializing = True
RuntimeError: Found no NVIDIA driver on your system. Please check that you have an NVIDIA GPU and installed a driver from http://www.nvidia.com/Download/index.aspx
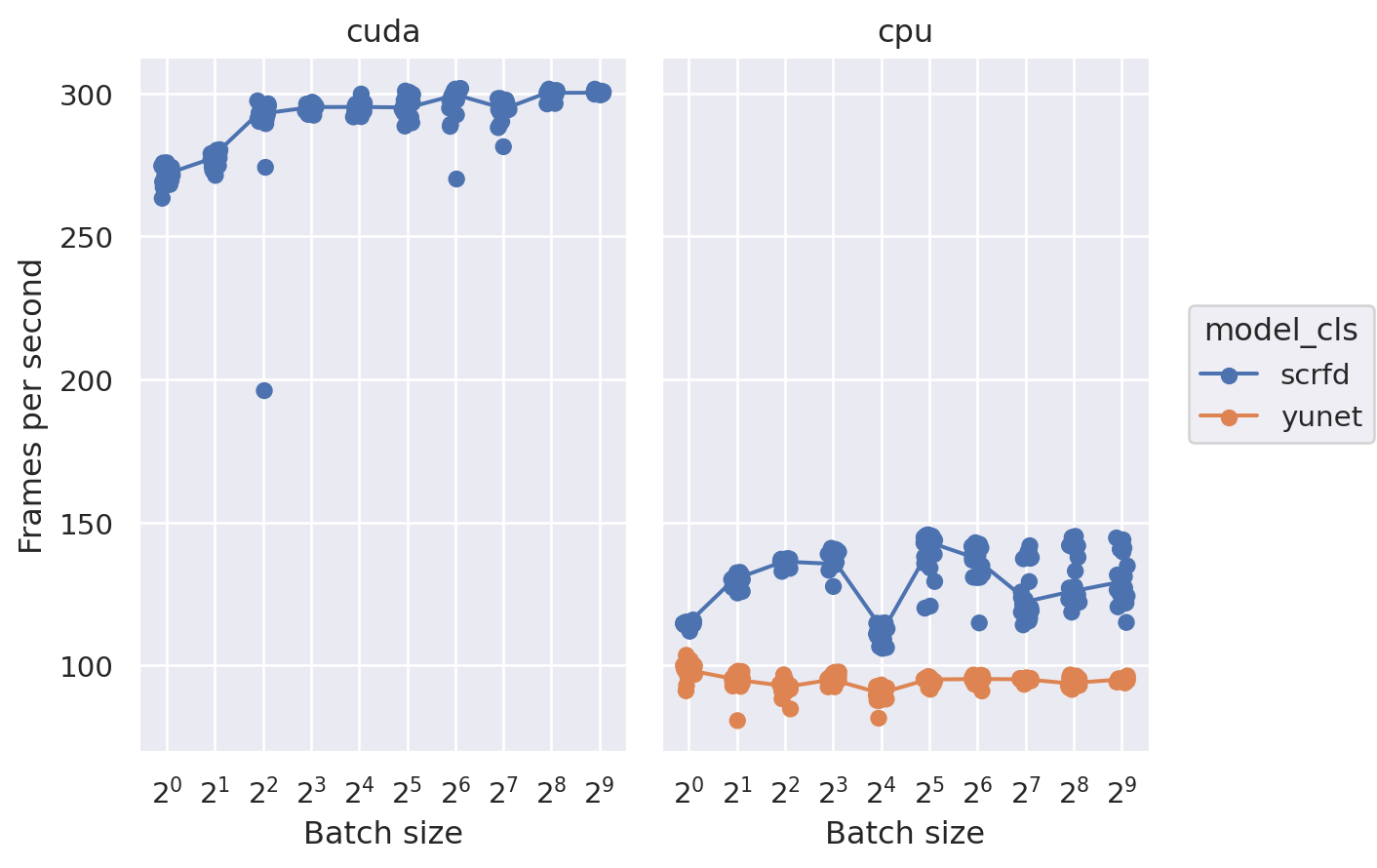
import seaborn.objects as so
df_detect['BPS'] = 1 / df_detect['duration']
df_detect['FPS'] = df_detect['BPS'] * df_detect['batch_size']
(
so.Plot(df_detect, x='batch_size', y='FPS', color='model_cls')
.facet(col="device")
.share(y=True, x=True)
.add(so.Dot(), so.Jitter(.3))
.add(so.Line(), so.Est('median', errorbar='sd'), so.Jitter(.3))
.scale(
x=so.Continuous(trans="log2").tick(count=len(params['batch_size']), between=(1, max(params['batch_size']))),
#y=so.Continuous(trans='log')
)
.label(
x="Batch size", y="Frames per second"
)
)
import torch
from medusa.recon import DecaReconModel
timer_ = FancyTimer()
params = {
"device": ['cuda', "cpu"],
"batch_size": [1, 2, 4, 8, 16, 32, 64, 128, 256, 512]
}
for p in timer_.iter(params):
model = DecaReconModel(name='emoca-coarse', device=p["device"])
img = get_example_image(device=p["device"])
img = img.repeat(p["batch_size"], 1, 1, 1)
with torch.inference_mode():
timer_.time(model, [img], n_warmup=3, repeats=5, params=p)
torch.cuda.empty_cache()
df_recon = timer_.to_df()
100%|██████████| 20/20 [04:54<00:00, 14.74s/it]
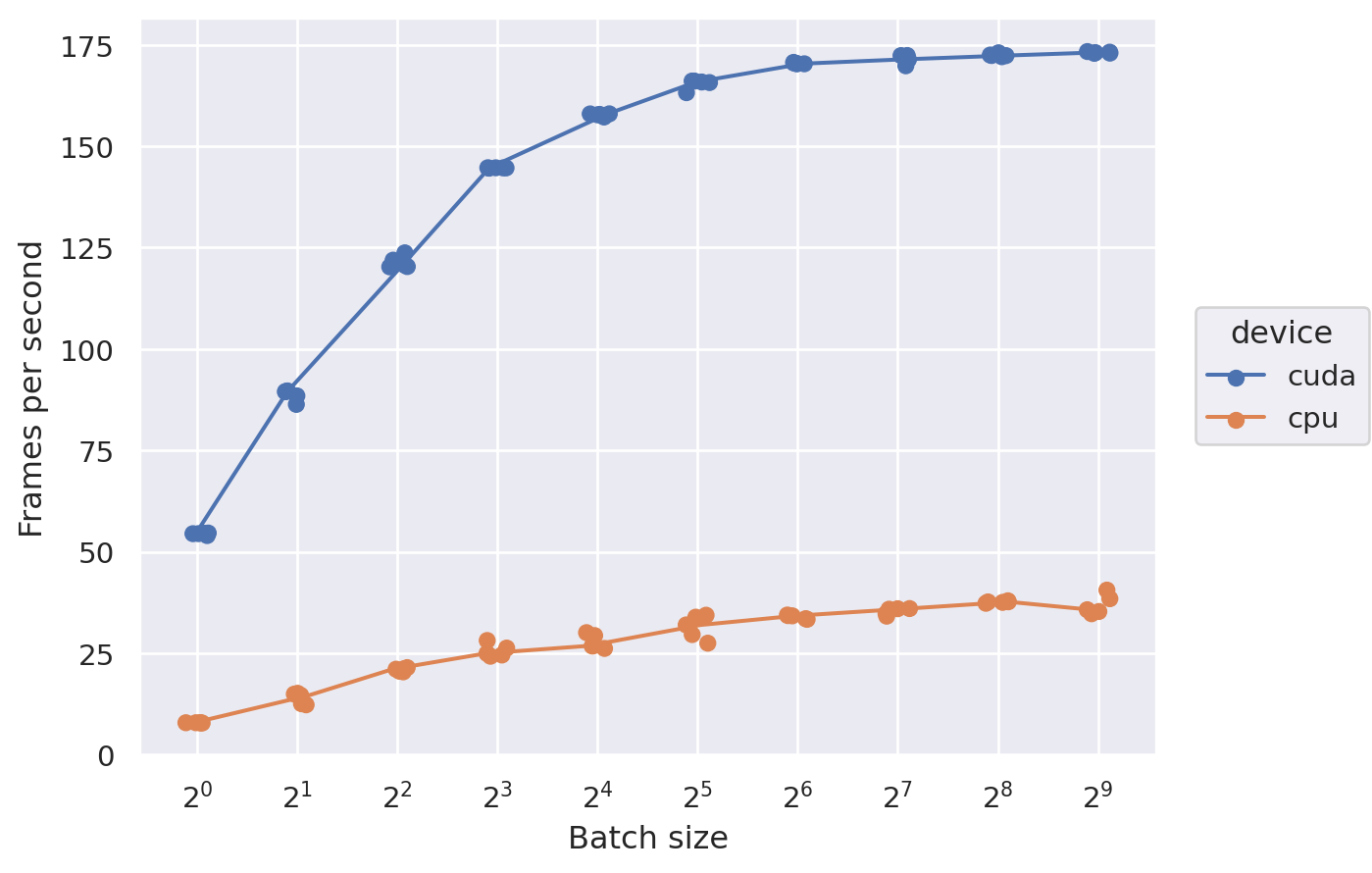
df_recon['BPS'] = 1 / df_recon['duration']
df_recon['FPS'] = df_recon['BPS'] * df_recon['batch_size']
(
so.Plot(df_recon, x='batch_size', y='FPS', color='device')
.add(so.Dot(), so.Jitter(.3))
.add(so.Line(), so.Est('median', errorbar=('ci', 99.99)), so.Jitter(.3))
.scale(
x=so.Continuous(trans="log2").tick(count=len(params['batch_size']), between=(1, max(params['batch_size']))),
)
.label(
x="Batch size", y="Frames per second"
)
)